Moved from this repo to its own repo so that the clone isn't so HUGE
This commit is contained in:
parent
0d7473eedb
commit
b9a3a118f5
17 changed files with 2 additions and 1725 deletions
|
|
@ -1,42 +1,6 @@
|
|||
|
||||

|
||||
|
||||
|
||||
|
||||
# PySimpleGUI openCV YOLO Deep Learning
|
||||
|
||||
To save room in the PySimpleGUI Repo, this project has been moved to its own repo on GitHub
|
||||
|
||||
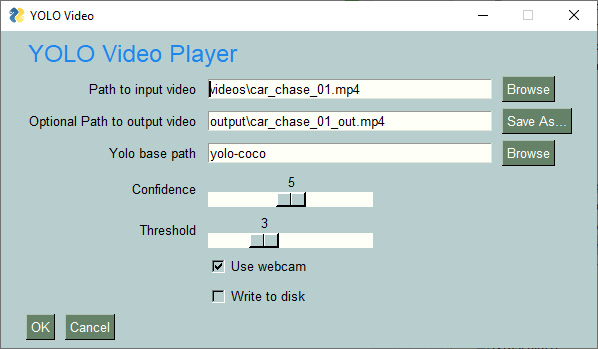
|
||||
|
||||
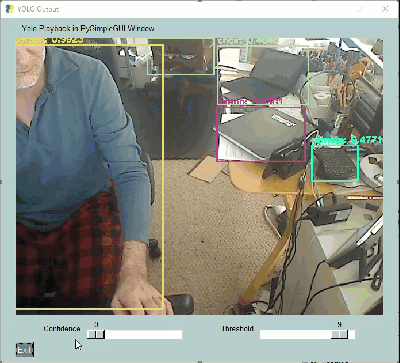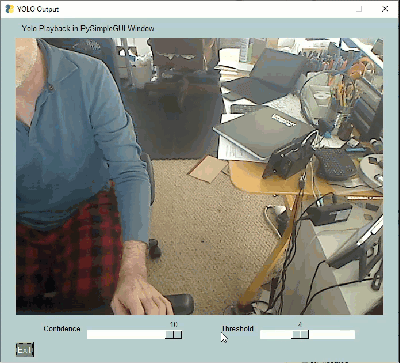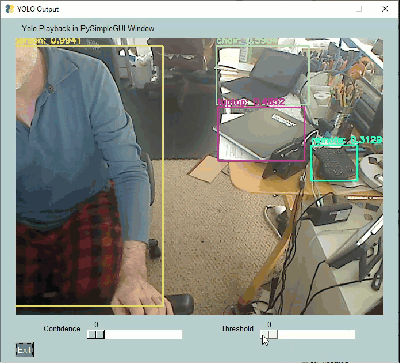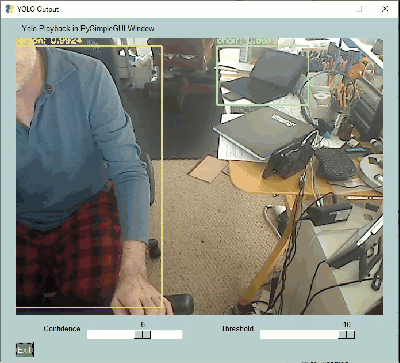
|
||||
|
||||
|
||||
|
||||
## Running the Demos
|
||||
|
||||
You will need to pip install openCV and PySimpleGUI
|
||||
```
|
||||
pip install opencv-python
|
||||
pip install pysimplegui
|
||||
```
|
||||
|
||||
Run any of the .py files in the top level directory:
|
||||
```
|
||||
yolo.py - single image processing
|
||||
yolo_video.py Video display
|
||||
yolo_video_with_webcam.py - webcam or file source. Option to write to hard drive
|
||||
```
|
||||
And you'll need the training data. It's 242 MB and too large for GitHub:
|
||||
https://www.dropbox.com/s/0pq7le6fwtbarkc/yolov3.weights?dl=1
|
||||
|
||||
## Learn More
|
||||
|
||||
This code has an article associated with it that will step you through the code (minus GUI part).
|
||||
|
||||
https://www.pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
|
||||
|
||||
|
||||
## Acknowledgements
|
||||
This software is provided by Dr. Adrian Rosebrock of the pyimagesearch organization.
|
||||
https://www.pyimagesearch.com
|
||||
|
||||
You'll now find the project at: https://github.com/PySimpleGUI/PySimpleGUI-YOLO
|
||||
|
|
|
|||
|
|
@ -1,222 +0,0 @@
|
|||
# YOLO object detection using a webcam
|
||||
# Exact same demo as the read from disk, but instead of disk a webcam is used.
|
||||
# import the necessary packages
|
||||
import numpy as np
|
||||
# import argparse
|
||||
import imutils
|
||||
import time
|
||||
import cv2
|
||||
import os
|
||||
import PySimpleGUIQt as sg
|
||||
|
||||
i_vid = r'videos\car_chase_01.mp4'
|
||||
o_vid = r'output\car_chase_01_out.mp4'
|
||||
y_path = r'yolo-coco'
|
||||
sg.ChangeLookAndFeel('LightGreen')
|
||||
layout = [
|
||||
[sg.Text('YOLO Video Player', size=(22,1), font=('Any',18),text_color='#1c86ee' ,justification='left')],
|
||||
[sg.Text('Path to input video'), sg.In(i_vid,size=(40,1), key='input'), sg.FileBrowse()],
|
||||
[sg.Text('Optional Path to output video'), sg.In(o_vid,size=(40,1), key='output'), sg.FileSaveAs()],
|
||||
[sg.Text('Yolo base path'), sg.In(y_path,size=(40,1), key='yolo'), sg.FolderBrowse()],
|
||||
[sg.Text('Confidence'), sg.Slider(range=(0,10),orientation='h', resolution=1, default_value=5, size=(15,15), key='confidence'), sg.T(' ', key='_CONF_OUT_')],
|
||||
[sg.Text('Threshold'), sg.Slider(range=(0,10), orientation='h', resolution=1, default_value=3, size=(15,15), key='threshold'), sg.T(' ', key='_THRESH_OUT_')],
|
||||
[sg.Text(' '*8), sg.Checkbox('Use webcam', key='_WEBCAM_')],
|
||||
[sg.Text(' '*8), sg.Checkbox('Write to disk', key='_DISK_')],
|
||||
[sg.OK(), sg.Cancel(), sg.Stretch()],
|
||||
]
|
||||
|
||||
win = sg.Window('YOLO Video',
|
||||
default_element_size=(21,1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout)
|
||||
event, values = win.Read()
|
||||
if event is None or event =='Cancel':
|
||||
exit()
|
||||
write_to_disk = values['_DISK_']
|
||||
use_webcam = values['_WEBCAM_']
|
||||
args = values
|
||||
|
||||
win.Close()
|
||||
|
||||
|
||||
# imgbytes = cv2.imencode('.png', image)[1].tobytes() # ditto
|
||||
gui_confidence = args["confidence"]/10
|
||||
gui_threshold = args["threshold"]/10
|
||||
# load the COCO class labels our YOLO model was trained on
|
||||
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
|
||||
LABELS = open(labelsPath).read().strip().split("\n")
|
||||
|
||||
# initialize a list of colors to represent each possible class label
|
||||
np.random.seed(42)
|
||||
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
|
||||
dtype="uint8")
|
||||
|
||||
# derive the paths to the YOLO weights and model configuration
|
||||
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
|
||||
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
|
||||
|
||||
# load our YOLO object detector trained on COCO dataset (80 classes)
|
||||
# and determine only the *output* layer names that we need from YOLO
|
||||
print("[INFO] loading YOLO from disk...")
|
||||
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
|
||||
ln = net.getLayerNames()
|
||||
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
|
||||
|
||||
# initialize the video stream, pointer to output video file, and
|
||||
# frame dimensions
|
||||
vs = cv2.VideoCapture(args["input"])
|
||||
writer = None
|
||||
(W, H) = (None, None)
|
||||
|
||||
# try to determine the total number of frames in the video file
|
||||
try:
|
||||
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
|
||||
else cv2.CAP_PROP_FRAME_COUNT
|
||||
total = int(vs.get(prop))
|
||||
print("[INFO] {} total frames in video".format(total))
|
||||
|
||||
# an error occurred while trying to determine the total
|
||||
# number of frames in the video file
|
||||
except:
|
||||
print("[INFO] could not determine # of frames in video")
|
||||
print("[INFO] no approx. completion time can be provided")
|
||||
total = -1
|
||||
|
||||
# loop over frames from the video file stream
|
||||
win_started = False
|
||||
if use_webcam:
|
||||
cap = cv2.VideoCapture(0)
|
||||
while True:
|
||||
# read the next frame from the file or webcam
|
||||
if use_webcam:
|
||||
grabbed, frame = cap.read()
|
||||
else:
|
||||
grabbed, frame = vs.read()
|
||||
|
||||
# if the frame was not grabbed, then we have reached the end
|
||||
# of the stream
|
||||
if not grabbed:
|
||||
break
|
||||
|
||||
# if the frame dimensions are empty, grab them
|
||||
if W is None or H is None:
|
||||
(H, W) = frame.shape[:2]
|
||||
|
||||
# construct a blob from the input frame and then perform a forward
|
||||
# pass of the YOLO object detector, giving us our bounding boxes
|
||||
# and associated probabilities
|
||||
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
|
||||
swapRB=True, crop=False)
|
||||
net.setInput(blob)
|
||||
start = time.time()
|
||||
layerOutputs = net.forward(ln)
|
||||
end = time.time()
|
||||
|
||||
# initialize our lists of detected bounding boxes, confidences,
|
||||
# and class IDs, respectively
|
||||
boxes = []
|
||||
confidences = []
|
||||
classIDs = []
|
||||
|
||||
# loop over each of the layer outputs
|
||||
for output in layerOutputs:
|
||||
# loop over each of the detections
|
||||
for detection in output:
|
||||
# extract the class ID and confidence (i.e., probability)
|
||||
# of the current object detection
|
||||
scores = detection[5:]
|
||||
classID = np.argmax(scores)
|
||||
confidence = scores[classID]
|
||||
|
||||
# filter out weak predictions by ensuring the detected
|
||||
# probability is greater than the minimum probability
|
||||
if confidence > gui_confidence:
|
||||
# scale the bounding box coordinates back relative to
|
||||
# the size of the image, keeping in mind that YOLO
|
||||
# actually returns the center (x, y)-coordinates of
|
||||
# the bounding box followed by the boxes' width and
|
||||
# height
|
||||
box = detection[0:4] * np.array([W, H, W, H])
|
||||
(centerX, centerY, width, height) = box.astype("int")
|
||||
|
||||
# use the center (x, y)-coordinates to derive the top
|
||||
# and and left corner of the bounding box
|
||||
x = int(centerX - (width / 2))
|
||||
y = int(centerY - (height / 2))
|
||||
|
||||
# update our list of bounding box coordinates,
|
||||
# confidences, and class IDs
|
||||
boxes.append([x, y, int(width), int(height)])
|
||||
confidences.append(float(confidence))
|
||||
classIDs.append(classID)
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping
|
||||
# bounding boxes
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, gui_confidence, gui_threshold)
|
||||
|
||||
# ensure at least one detection exists
|
||||
if len(idxs) > 0:
|
||||
# loop over the indexes we are keeping
|
||||
for i in idxs.flatten():
|
||||
# extract the bounding box coordinates
|
||||
(x, y) = (boxes[i][0], boxes[i][1])
|
||||
(w, h) = (boxes[i][2], boxes[i][3])
|
||||
|
||||
# draw a bounding box rectangle and label on the frame
|
||||
color = [int(c) for c in COLORS[classIDs[i]]]
|
||||
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
|
||||
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
|
||||
confidences[i])
|
||||
cv2.putText(frame, text, (x, y - 5),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
|
||||
if write_to_disk:
|
||||
#check if the video writer is None
|
||||
if writer is None:
|
||||
# initialize our video writer
|
||||
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
|
||||
writer = cv2.VideoWriter(args["output"], fourcc, 30,
|
||||
(frame.shape[1], frame.shape[0]), True)
|
||||
|
||||
# some information on processing single frame
|
||||
if total > 0:
|
||||
elap = (end - start)
|
||||
print("[INFO] single frame took {:.4f} seconds".format(elap))
|
||||
print("[INFO] estimated total time to finish: {:.4f}".format(
|
||||
elap * total))
|
||||
|
||||
#write the output frame to disk
|
||||
writer.write(frame)
|
||||
imgbytes = cv2.imencode('.png', frame)[1].tobytes() # ditto
|
||||
|
||||
if not win_started:
|
||||
win_started = True
|
||||
layout = [
|
||||
[sg.Text('Yolo Playback in PySimpleGUI Window', size=(30,1))],
|
||||
[sg.Image(data=imgbytes, key='_IMAGE_')],
|
||||
[sg.Text('Confidence'),
|
||||
sg.Slider(range=(0, 10), orientation='h', resolution=1, default_value=5, size=(15, 15), key='confidence'),
|
||||
sg.Text('Threshold'),
|
||||
sg.Slider(range=(0, 10), orientation='h', resolution=1, default_value=3, size=(15, 15), key='threshold')],
|
||||
[sg.Exit()]
|
||||
]
|
||||
win = sg.Window('YOLO Output',
|
||||
default_element_size=(14, 1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout).Finalize()
|
||||
image_elem = win.FindElement('_IMAGE_')
|
||||
else:
|
||||
image_elem.Update(data=imgbytes)
|
||||
|
||||
event, values = win.Read(timeout=0)
|
||||
if event is None or event == 'Exit':
|
||||
break
|
||||
gui_confidence = values['confidence']/10
|
||||
gui_threshold = values['threshold']/10
|
||||
|
||||
|
||||
win.Close()
|
||||
|
||||
# release the file pointers
|
||||
print("[INFO] cleaning up...")
|
||||
writer.release() if writer is not None else None
|
||||
vs.release()
|
||||
Binary file not shown.
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 54 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 222 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 68 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 290 KiB |
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -1,80 +0,0 @@
|
|||
person
|
||||
bicycle
|
||||
car
|
||||
motorbike
|
||||
aeroplane
|
||||
bus
|
||||
train
|
||||
truck
|
||||
boat
|
||||
traffic light
|
||||
fire hydrant
|
||||
stop sign
|
||||
parking meter
|
||||
bench
|
||||
bird
|
||||
cat
|
||||
dog
|
||||
horse
|
||||
sheep
|
||||
cow
|
||||
elephant
|
||||
bear
|
||||
zebra
|
||||
giraffe
|
||||
backpack
|
||||
umbrella
|
||||
handbag
|
||||
tie
|
||||
suitcase
|
||||
frisbee
|
||||
skis
|
||||
snowboard
|
||||
sports ball
|
||||
kite
|
||||
baseball bat
|
||||
baseball glove
|
||||
skateboard
|
||||
surfboard
|
||||
tennis racket
|
||||
bottle
|
||||
wine glass
|
||||
cup
|
||||
fork
|
||||
knife
|
||||
spoon
|
||||
bowl
|
||||
banana
|
||||
apple
|
||||
sandwich
|
||||
orange
|
||||
broccoli
|
||||
carrot
|
||||
hot dog
|
||||
pizza
|
||||
donut
|
||||
cake
|
||||
chair
|
||||
sofa
|
||||
pottedplant
|
||||
bed
|
||||
diningtable
|
||||
toilet
|
||||
tvmonitor
|
||||
laptop
|
||||
mouse
|
||||
remote
|
||||
keyboard
|
||||
cell phone
|
||||
microwave
|
||||
oven
|
||||
toaster
|
||||
sink
|
||||
refrigerator
|
||||
book
|
||||
clock
|
||||
vase
|
||||
scissors
|
||||
teddy bear
|
||||
hair drier
|
||||
toothbrush
|
||||
|
|
@ -1,789 +0,0 @@
|
|||
[net]
|
||||
# Testing
|
||||
# batch=1
|
||||
# subdivisions=1
|
||||
# Training
|
||||
batch=64
|
||||
subdivisions=16
|
||||
width=608
|
||||
height=608
|
||||
channels=3
|
||||
momentum=0.9
|
||||
decay=0.0005
|
||||
angle=0
|
||||
saturation = 1.5
|
||||
exposure = 1.5
|
||||
hue=.1
|
||||
|
||||
learning_rate=0.001
|
||||
burn_in=1000
|
||||
max_batches = 500200
|
||||
policy=steps
|
||||
steps=400000,450000
|
||||
scales=.1,.1
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=32
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=64
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
# Downsample
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=2
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=1024
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[shortcut]
|
||||
from=-3
|
||||
activation=linear
|
||||
|
||||
######################
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=512
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=1024
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 6,7,8
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 61
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=256
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=512
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 3,4,5
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
||||
|
||||
[route]
|
||||
layers = -4
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[upsample]
|
||||
stride=2
|
||||
|
||||
[route]
|
||||
layers = -1, 36
|
||||
|
||||
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
filters=128
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
batch_normalize=1
|
||||
size=3
|
||||
stride=1
|
||||
pad=1
|
||||
filters=256
|
||||
activation=leaky
|
||||
|
||||
[convolutional]
|
||||
size=1
|
||||
stride=1
|
||||
pad=1
|
||||
filters=255
|
||||
activation=linear
|
||||
|
||||
|
||||
[yolo]
|
||||
mask = 0,1,2
|
||||
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
|
||||
classes=80
|
||||
num=9
|
||||
jitter=.3
|
||||
ignore_thresh = .7
|
||||
truth_thresh = 1
|
||||
random=1
|
||||
|
||||
|
|
@ -1,3 +0,0 @@
|
|||
You must download this 242 MB file in order to run the Yolo demo program
|
||||
|
||||
https://www.dropbox.com/s/0pq7le6fwtbarkc/yolov3.weights?dl=1
|
||||
|
|
@ -1,164 +0,0 @@
|
|||
# USAGE
|
||||
# python yolo.py --image images/baggage_claim.jpg --yolo yolo-coco
|
||||
"""
|
||||
A Yolo image processor with a GUI front-end
|
||||
The original code was command line driven. Now these parameters are collected via a GUI
|
||||
|
||||
old usage: yolo_video.py [-h] -i INPUT -o OUTPUT -y YOLO [-c CONFIDENCE]
|
||||
[-t THRESHOLD]
|
||||
"""
|
||||
|
||||
# import the necessary packages
|
||||
import numpy as np
|
||||
import argparse
|
||||
import time
|
||||
import cv2
|
||||
import os
|
||||
import PySimpleGUIQt as sg
|
||||
|
||||
layout = [
|
||||
[sg.Text('YOLO')],
|
||||
[sg.Text('Path to image'), sg.In(r'C:/Python/PycharmProjects/YoloObjectDetection/images/baggage_claim.jpg',size=(40,1), key='image'), sg.FileBrowse()],
|
||||
[sg.Text('Yolo base path'), sg.In(r'yolo-coco',size=(40,1), key='yolo'), sg.FolderBrowse()],
|
||||
[sg.Text('Confidence'), sg.Slider(range=(0,10),orientation='h', resolution=1, default_value=5, size=(15,15), key='confidence')],
|
||||
[sg.Text('Threshold'), sg.Slider(range=(0,10), orientation='h', resolution=1, default_value=3, size=(15,15), key='threshold')],
|
||||
[sg.OK(), sg.Cancel(), sg.Stretch()]
|
||||
]
|
||||
|
||||
win = sg.Window('YOLO',
|
||||
default_element_size=(14,1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout)
|
||||
event, values = win.Read()
|
||||
args = values
|
||||
win.Close()
|
||||
# construct the argument parse and parse the arguments
|
||||
# ap = argparse.ArgumentParser()
|
||||
# ap.add_argument("-i", "--image", required=True,
|
||||
# help="path to input image")
|
||||
# ap.add_argument("-y", "--yolo", required=True,
|
||||
# help="base path to YOLO directory")
|
||||
# ap.add_argument("-c", "--confidence", type=float, default=0.5,
|
||||
# help="minimum probability to filter weak detections")
|
||||
# ap.add_argument("-t", "--threshold", type=float, default=0.3,
|
||||
# help="threshold when applyong non-maxima suppression")
|
||||
# args = vars(ap.parse_args())
|
||||
|
||||
# load the COCO class labels our YOLO model was trained on
|
||||
args['threshold'] = float(args['threshold']/10)
|
||||
args['confidence'] = float(args['confidence']/10)
|
||||
|
||||
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
|
||||
LABELS = open(labelsPath).read().strip().split("\n")
|
||||
|
||||
# initialize a list of colors to represent each possible class label
|
||||
np.random.seed(42)
|
||||
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
|
||||
dtype="uint8")
|
||||
|
||||
# derive the paths to the YOLO weights and model configuration
|
||||
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
|
||||
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
|
||||
|
||||
# load our YOLO object detector trained on COCO dataset (80 classes)
|
||||
print("[INFO] loading YOLO from disk...")
|
||||
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
|
||||
|
||||
# load our input image and grab its spatial dimensions
|
||||
image = cv2.imread(args["image"])
|
||||
|
||||
(H, W) = image.shape[:2]
|
||||
|
||||
# determine only the *output* layer names that we need from YOLO
|
||||
ln = net.getLayerNames()
|
||||
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
|
||||
|
||||
# construct a blob from the input image and then perform a forward
|
||||
# pass of the YOLO object detector, giving us our bounding boxes and
|
||||
# associated probabilities
|
||||
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),
|
||||
swapRB=True, crop=False)
|
||||
net.setInput(blob)
|
||||
start = time.time()
|
||||
layerOutputs = net.forward(ln)
|
||||
end = time.time()
|
||||
|
||||
# show timing information on YOLO
|
||||
print("[INFO] YOLO took {:.6f} seconds".format(end - start))
|
||||
|
||||
# initialize our lists of detected bounding boxes, confidences, and
|
||||
# class IDs, respectively
|
||||
boxes = []
|
||||
confidences = []
|
||||
classIDs = []
|
||||
|
||||
# loop over each of the layer outputs
|
||||
for output in layerOutputs:
|
||||
# loop over each of the detections
|
||||
for detection in output:
|
||||
# extract the class ID and confidence (i.e., probability) of
|
||||
# the current object detection
|
||||
scores = detection[5:]
|
||||
classID = np.argmax(scores)
|
||||
confidence = scores[classID]
|
||||
|
||||
# filter out weak predictions by ensuring the detected
|
||||
# probability is greater than the minimum probability
|
||||
if confidence > args["confidence"]:
|
||||
# scale the bounding box coordinates back relative to the
|
||||
# size of the image, keeping in mind that YOLO actually
|
||||
# returns the center (x, y)-coordinates of the bounding
|
||||
# box followed by the boxes' width and height
|
||||
box = detection[0:4] * np.array([W, H, W, H])
|
||||
(centerX, centerY, width, height) = box.astype("int")
|
||||
|
||||
# use the center (x, y)-coordinates to derive the top and
|
||||
# and left corner of the bounding box
|
||||
x = int(centerX - (width / 2))
|
||||
y = int(centerY - (height / 2))
|
||||
|
||||
# update our list of bounding box coordinates, confidences,
|
||||
# and class IDs
|
||||
boxes.append([x, y, int(width), int(height)])
|
||||
confidences.append(float(confidence))
|
||||
classIDs.append(classID)
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping bounding
|
||||
# boxes
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, args["confidence"],
|
||||
args["threshold"])
|
||||
|
||||
# ensure at least one detection exists
|
||||
if len(idxs) > 0:
|
||||
# loop over the indexes we are keeping
|
||||
for i in idxs.flatten():
|
||||
# extract the bounding box coordinates
|
||||
(x, y) = (boxes[i][0], boxes[i][1])
|
||||
(w, h) = (boxes[i][2], boxes[i][3])
|
||||
|
||||
# draw a bounding box rectangle and label on the image
|
||||
color = [int(c) for c in COLORS[classIDs[i]]]
|
||||
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
|
||||
text = "{}: {:.4f}".format(LABELS[classIDs[i]], confidences[i])
|
||||
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
|
||||
0.5, color, 2)
|
||||
|
||||
# show the output image
|
||||
imgbytes = cv2.imencode('.png', image)[1].tobytes() # ditto
|
||||
|
||||
|
||||
layout = [
|
||||
[sg.Text('Yolo Output')],
|
||||
[sg.Image(data=imgbytes)],
|
||||
[sg.OK(), sg.Cancel()]
|
||||
]
|
||||
|
||||
win = sg.Window('YOLO',
|
||||
default_element_size=(14,1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout)
|
||||
event, values = win.Read()
|
||||
win.Close()
|
||||
|
||||
# cv2.imshow("Image", image)
|
||||
cv2.waitKey(0)
|
||||
|
|
@ -1,207 +0,0 @@
|
|||
# USAGE
|
||||
# python yolo_video.py --input videos/airport.mp4 --output output/airport_output.avi --yolo yolo-coco
|
||||
|
||||
# import the necessary packages
|
||||
import numpy as np
|
||||
# import argparse
|
||||
import imutils
|
||||
import time
|
||||
import cv2
|
||||
import os
|
||||
import PySimpleGUI as sg
|
||||
|
||||
i_vid = r'videos\car_chase_01.mp4'
|
||||
# o_vid = r'videos\car_chase_01_out.mp4'
|
||||
y_path = r'yolo-coco'
|
||||
layout = [
|
||||
[sg.Text('YOLO Video Player', size=(18,1), font=('Any',18),text_color='#1c86ee' ,justification='left')],
|
||||
[sg.Text('Path to input video'), sg.In(i_vid,size=(40,1), key='input'), sg.FileBrowse()],
|
||||
# [sg.Text('Path to output video'), sg.In(o_vid,size=(40,1), key='output'), sg.FileSaveAs()],
|
||||
[sg.Text('Yolo base path'), sg.In(y_path,size=(40,1), key='yolo'), sg.FolderBrowse()],
|
||||
[sg.Text('Confidence'), sg.Slider(range=(0,1),orientation='h', resolution=.1, default_value=.5, size=(15,15), key='confidence')],
|
||||
[sg.Text('Threshold'), sg.Slider(range=(0,1), orientation='h', resolution=.1, default_value=.3, size=(15,15), key='threshold')],
|
||||
[sg.OK(), sg.Cancel()]
|
||||
]
|
||||
|
||||
win = sg.Window('YOLO Video',
|
||||
default_element_size=(14,1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout)
|
||||
event, values = win.Read()
|
||||
if event is None or event =='Cancel':
|
||||
exit()
|
||||
args = values
|
||||
|
||||
win.Close()
|
||||
|
||||
|
||||
# imgbytes = cv2.imencode('.png', image)[1].tobytes() # ditto
|
||||
|
||||
# load the COCO class labels our YOLO model was trained on
|
||||
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
|
||||
LABELS = open(labelsPath).read().strip().split("\n")
|
||||
|
||||
# initialize a list of colors to represent each possible class label
|
||||
np.random.seed(42)
|
||||
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
|
||||
dtype="uint8")
|
||||
|
||||
# derive the paths to the YOLO weights and model configuration
|
||||
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
|
||||
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
|
||||
|
||||
# load our YOLO object detector trained on COCO dataset (80 classes)
|
||||
# and determine only the *output* layer names that we need from YOLO
|
||||
print("[INFO] loading YOLO from disk...")
|
||||
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
|
||||
ln = net.getLayerNames()
|
||||
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
|
||||
|
||||
# initialize the video stream, pointer to output video file, and
|
||||
# frame dimensions
|
||||
vs = cv2.VideoCapture(args["input"])
|
||||
writer = None
|
||||
(W, H) = (None, None)
|
||||
|
||||
# try to determine the total number of frames in the video file
|
||||
try:
|
||||
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
|
||||
else cv2.CAP_PROP_FRAME_COUNT
|
||||
total = int(vs.get(prop))
|
||||
print("[INFO] {} total frames in video".format(total))
|
||||
|
||||
# an error occurred while trying to determine the total
|
||||
# number of frames in the video file
|
||||
except:
|
||||
print("[INFO] could not determine # of frames in video")
|
||||
print("[INFO] no approx. completion time can be provided")
|
||||
total = -1
|
||||
|
||||
# loop over frames from the video file stream
|
||||
win_started = False
|
||||
while True:
|
||||
# read the next frame from the file
|
||||
(grabbed, frame) = vs.read()
|
||||
|
||||
# if the frame was not grabbed, then we have reached the end
|
||||
# of the stream
|
||||
if not grabbed:
|
||||
break
|
||||
|
||||
# if the frame dimensions are empty, grab them
|
||||
if W is None or H is None:
|
||||
(H, W) = frame.shape[:2]
|
||||
|
||||
# construct a blob from the input frame and then perform a forward
|
||||
# pass of the YOLO object detector, giving us our bounding boxes
|
||||
# and associated probabilities
|
||||
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
|
||||
swapRB=True, crop=False)
|
||||
net.setInput(blob)
|
||||
start = time.time()
|
||||
layerOutputs = net.forward(ln)
|
||||
end = time.time()
|
||||
|
||||
# initialize our lists of detected bounding boxes, confidences,
|
||||
# and class IDs, respectively
|
||||
boxes = []
|
||||
confidences = []
|
||||
classIDs = []
|
||||
|
||||
# loop over each of the layer outputs
|
||||
for output in layerOutputs:
|
||||
# loop over each of the detections
|
||||
for detection in output:
|
||||
# extract the class ID and confidence (i.e., probability)
|
||||
# of the current object detection
|
||||
scores = detection[5:]
|
||||
classID = np.argmax(scores)
|
||||
confidence = scores[classID]
|
||||
|
||||
# filter out weak predictions by ensuring the detected
|
||||
# probability is greater than the minimum probability
|
||||
if confidence > args["confidence"]:
|
||||
# scale the bounding box coordinates back relative to
|
||||
# the size of the image, keeping in mind that YOLO
|
||||
# actually returns the center (x, y)-coordinates of
|
||||
# the bounding box followed by the boxes' width and
|
||||
# height
|
||||
box = detection[0:4] * np.array([W, H, W, H])
|
||||
(centerX, centerY, width, height) = box.astype("int")
|
||||
|
||||
# use the center (x, y)-coordinates to derive the top
|
||||
# and and left corner of the bounding box
|
||||
x = int(centerX - (width / 2))
|
||||
y = int(centerY - (height / 2))
|
||||
|
||||
# update our list of bounding box coordinates,
|
||||
# confidences, and class IDs
|
||||
boxes.append([x, y, int(width), int(height)])
|
||||
confidences.append(float(confidence))
|
||||
classIDs.append(classID)
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping
|
||||
# bounding boxes
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, args["confidence"],
|
||||
args["threshold"])
|
||||
|
||||
# ensure at least one detection exists
|
||||
if len(idxs) > 0:
|
||||
# loop over the indexes we are keeping
|
||||
for i in idxs.flatten():
|
||||
# extract the bounding box coordinates
|
||||
(x, y) = (boxes[i][0], boxes[i][1])
|
||||
(w, h) = (boxes[i][2], boxes[i][3])
|
||||
|
||||
# draw a bounding box rectangle and label on the frame
|
||||
color = [int(c) for c in COLORS[classIDs[i]]]
|
||||
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
|
||||
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
|
||||
confidences[i])
|
||||
cv2.putText(frame, text, (x, y - 5),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
|
||||
|
||||
# check if the video writer is None
|
||||
# if writer is None:
|
||||
# # initialize our video writer
|
||||
# fourcc = cv2.VideoWriter_fourcc(*"MJPG")
|
||||
# writer = cv2.VideoWriter(args["output"], fourcc, 30,
|
||||
# (frame.shape[1], frame.shape[0]), True)
|
||||
#
|
||||
# # some information on processing single frame
|
||||
# if total > 0:
|
||||
# elap = (end - start)
|
||||
# print("[INFO] single frame took {:.4f} seconds".format(elap))
|
||||
# print("[INFO] estimated total time to finish: {:.4f}".format(
|
||||
# elap * total))
|
||||
|
||||
# write the output frame to disk
|
||||
# writer.write(frame)
|
||||
imgbytes = cv2.imencode('.png', frame)[1].tobytes() # ditto
|
||||
|
||||
if not win_started:
|
||||
win_started = True
|
||||
layout = [
|
||||
[sg.Text('Yolo Output')],
|
||||
[sg.Image(data=imgbytes, key='_IMAGE_')],
|
||||
[sg.Exit()]
|
||||
]
|
||||
win = sg.Window('YOLO Output',
|
||||
default_element_size=(14, 1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout).Finalize()
|
||||
image_elem = win.FindElement('_IMAGE_')
|
||||
else:
|
||||
image_elem.Update(data=imgbytes)
|
||||
|
||||
event, values = win.Read(timeout=0)
|
||||
if event is None or event == 'Exit':
|
||||
break
|
||||
|
||||
|
||||
win.Close()
|
||||
|
||||
# release the file pointers
|
||||
print("[INFO] cleaning up...")
|
||||
writer.release()
|
||||
vs.release()
|
||||
|
|
@ -1,222 +0,0 @@
|
|||
# YOLO object detection using a webcam
|
||||
# Exact same demo as the read from disk, but instead of disk a webcam is used.
|
||||
# import the necessary packages
|
||||
import numpy as np
|
||||
# import argparse
|
||||
import imutils
|
||||
import time
|
||||
import cv2
|
||||
import os
|
||||
import PySimpleGUI as sg
|
||||
|
||||
i_vid = r'videos\car_chase_01.mp4'
|
||||
o_vid = r'output\car_chase_01_out.mp4'
|
||||
y_path = r'yolo-coco'
|
||||
sg.ChangeLookAndFeel('LightGreen')
|
||||
layout = [
|
||||
[sg.Text('YOLO Video Player', size=(18,1), font=('Any',18),text_color='#1c86ee' ,justification='left')],
|
||||
[sg.Text('Path to input video'), sg.In(i_vid,size=(40,1), key='input'), sg.FileBrowse()],
|
||||
[sg.Text('Optional Path to output video'), sg.In(o_vid,size=(40,1), key='output'), sg.FileSaveAs()],
|
||||
[sg.Text('Yolo base path'), sg.In(y_path,size=(40,1), key='yolo'), sg.FolderBrowse()],
|
||||
[sg.Text('Confidence'), sg.Slider(range=(0,1),orientation='h', resolution=.1, default_value=.5, size=(15,15), key='confidence')],
|
||||
[sg.Text('Threshold'), sg.Slider(range=(0,1), orientation='h', resolution=.1, default_value=.3, size=(15,15), key='threshold')],
|
||||
[sg.Text(' '*8), sg.Checkbox('Use webcam', key='_WEBCAM_')],
|
||||
[sg.Text(' '*8), sg.Checkbox('Write to disk', key='_DISK_')],
|
||||
[sg.OK(), sg.Cancel()]
|
||||
]
|
||||
|
||||
win = sg.Window('YOLO Video',
|
||||
default_element_size=(21,1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout)
|
||||
event, values = win.Read()
|
||||
if event is None or event =='Cancel':
|
||||
exit()
|
||||
write_to_disk = values['_DISK_']
|
||||
use_webcam = values['_WEBCAM_']
|
||||
args = values
|
||||
|
||||
win.Close()
|
||||
|
||||
|
||||
# imgbytes = cv2.imencode('.png', image)[1].tobytes() # ditto
|
||||
gui_confidence = args["confidence"]
|
||||
gui_threshold = args["threshold"]
|
||||
# load the COCO class labels our YOLO model was trained on
|
||||
labelsPath = os.path.sep.join([args["yolo"], "coco.names"])
|
||||
LABELS = open(labelsPath).read().strip().split("\n")
|
||||
|
||||
# initialize a list of colors to represent each possible class label
|
||||
np.random.seed(42)
|
||||
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
|
||||
dtype="uint8")
|
||||
|
||||
# derive the paths to the YOLO weights and model configuration
|
||||
weightsPath = os.path.sep.join([args["yolo"], "yolov3.weights"])
|
||||
configPath = os.path.sep.join([args["yolo"], "yolov3.cfg"])
|
||||
|
||||
# load our YOLO object detector trained on COCO dataset (80 classes)
|
||||
# and determine only the *output* layer names that we need from YOLO
|
||||
print("[INFO] loading YOLO from disk...")
|
||||
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
|
||||
ln = net.getLayerNames()
|
||||
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
|
||||
|
||||
# initialize the video stream, pointer to output video file, and
|
||||
# frame dimensions
|
||||
vs = cv2.VideoCapture(args["input"])
|
||||
writer = None
|
||||
(W, H) = (None, None)
|
||||
|
||||
# try to determine the total number of frames in the video file
|
||||
try:
|
||||
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
|
||||
else cv2.CAP_PROP_FRAME_COUNT
|
||||
total = int(vs.get(prop))
|
||||
print("[INFO] {} total frames in video".format(total))
|
||||
|
||||
# an error occurred while trying to determine the total
|
||||
# number of frames in the video file
|
||||
except:
|
||||
print("[INFO] could not determine # of frames in video")
|
||||
print("[INFO] no approx. completion time can be provided")
|
||||
total = -1
|
||||
|
||||
# loop over frames from the video file stream
|
||||
win_started = False
|
||||
if use_webcam:
|
||||
cap = cv2.VideoCapture(0)
|
||||
while True:
|
||||
# read the next frame from the file or webcam
|
||||
if use_webcam:
|
||||
grabbed, frame = cap.read()
|
||||
else:
|
||||
grabbed, frame = vs.read()
|
||||
|
||||
# if the frame was not grabbed, then we have reached the end
|
||||
# of the stream
|
||||
if not grabbed:
|
||||
break
|
||||
|
||||
# if the frame dimensions are empty, grab them
|
||||
if W is None or H is None:
|
||||
(H, W) = frame.shape[:2]
|
||||
|
||||
# construct a blob from the input frame and then perform a forward
|
||||
# pass of the YOLO object detector, giving us our bounding boxes
|
||||
# and associated probabilities
|
||||
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
|
||||
swapRB=True, crop=False)
|
||||
net.setInput(blob)
|
||||
start = time.time()
|
||||
layerOutputs = net.forward(ln)
|
||||
end = time.time()
|
||||
|
||||
# initialize our lists of detected bounding boxes, confidences,
|
||||
# and class IDs, respectively
|
||||
boxes = []
|
||||
confidences = []
|
||||
classIDs = []
|
||||
|
||||
# loop over each of the layer outputs
|
||||
for output in layerOutputs:
|
||||
# loop over each of the detections
|
||||
for detection in output:
|
||||
# extract the class ID and confidence (i.e., probability)
|
||||
# of the current object detection
|
||||
scores = detection[5:]
|
||||
classID = np.argmax(scores)
|
||||
confidence = scores[classID]
|
||||
|
||||
# filter out weak predictions by ensuring the detected
|
||||
# probability is greater than the minimum probability
|
||||
if confidence > gui_confidence:
|
||||
# scale the bounding box coordinates back relative to
|
||||
# the size of the image, keeping in mind that YOLO
|
||||
# actually returns the center (x, y)-coordinates of
|
||||
# the bounding box followed by the boxes' width and
|
||||
# height
|
||||
box = detection[0:4] * np.array([W, H, W, H])
|
||||
(centerX, centerY, width, height) = box.astype("int")
|
||||
|
||||
# use the center (x, y)-coordinates to derive the top
|
||||
# and and left corner of the bounding box
|
||||
x = int(centerX - (width / 2))
|
||||
y = int(centerY - (height / 2))
|
||||
|
||||
# update our list of bounding box coordinates,
|
||||
# confidences, and class IDs
|
||||
boxes.append([x, y, int(width), int(height)])
|
||||
confidences.append(float(confidence))
|
||||
classIDs.append(classID)
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping
|
||||
# bounding boxes
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, gui_confidence, gui_threshold)
|
||||
|
||||
# ensure at least one detection exists
|
||||
if len(idxs) > 0:
|
||||
# loop over the indexes we are keeping
|
||||
for i in idxs.flatten():
|
||||
# extract the bounding box coordinates
|
||||
(x, y) = (boxes[i][0], boxes[i][1])
|
||||
(w, h) = (boxes[i][2], boxes[i][3])
|
||||
|
||||
# draw a bounding box rectangle and label on the frame
|
||||
color = [int(c) for c in COLORS[classIDs[i]]]
|
||||
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
|
||||
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
|
||||
confidences[i])
|
||||
cv2.putText(frame, text, (x, y - 5),
|
||||
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
|
||||
if write_to_disk:
|
||||
#check if the video writer is None
|
||||
if writer is None:
|
||||
# initialize our video writer
|
||||
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
|
||||
writer = cv2.VideoWriter(args["output"], fourcc, 30,
|
||||
(frame.shape[1], frame.shape[0]), True)
|
||||
|
||||
# some information on processing single frame
|
||||
if total > 0:
|
||||
elap = (end - start)
|
||||
print("[INFO] single frame took {:.4f} seconds".format(elap))
|
||||
print("[INFO] estimated total time to finish: {:.4f}".format(
|
||||
elap * total))
|
||||
|
||||
#write the output frame to disk
|
||||
writer.write(frame)
|
||||
imgbytes = cv2.imencode('.png', frame)[1].tobytes() # ditto
|
||||
|
||||
if not win_started:
|
||||
win_started = True
|
||||
layout = [
|
||||
[sg.Text('Yolo Playback in PySimpleGUI Window', size=(30,1))],
|
||||
[sg.Image(data=imgbytes, key='_IMAGE_')],
|
||||
[sg.Text('Confidence'),
|
||||
sg.Slider(range=(0, 1), orientation='h', resolution=.1, default_value=.5, size=(15, 15), key='confidence'),
|
||||
sg.Text('Threshold'),
|
||||
sg.Slider(range=(0, 1), orientation='h', resolution=.1, default_value=.3, size=(15, 15), key='threshold')],
|
||||
[sg.Exit()]
|
||||
]
|
||||
win = sg.Window('YOLO Output',
|
||||
default_element_size=(14, 1),
|
||||
text_justification='right',
|
||||
auto_size_text=False).Layout(layout).Finalize()
|
||||
image_elem = win.FindElement('_IMAGE_')
|
||||
else:
|
||||
image_elem.Update(data=imgbytes)
|
||||
|
||||
event, values = win.Read(timeout=0)
|
||||
if event is None or event == 'Exit':
|
||||
break
|
||||
gui_confidence = values['confidence']
|
||||
gui_threshold = values['threshold']
|
||||
|
||||
|
||||
win.Close()
|
||||
|
||||
# release the file pointers
|
||||
print("[INFO] cleaning up...")
|
||||
writer.release() if writer is not None else None
|
||||
vs.release()
|
||||
Loading…
Add table
Add a link
Reference in a new issue